
Kevin Cox and Lisa Schutz
The Problem – Billions In Misdirected Activity
The problem of not having a clear view of customers across organisations or groups of organisations such as Government departments, costs billions a year. The cost occurs in three ways, the billions in misdirected services that could be saved if the right people had the right information. The costs can be human lives, time wasted and organisational costs in cleaning up data and cleaning up messes after data gets mismatched. Single Customer View is in unfortunate phrase, because it misspecifies what is at stake here – nothing less than getting the job done right (whatever it is) first time.
Traditional Indexes Take Effort
Traditional approaches to achieve a single view of the customer relationship (or the citizen) work on very old school models of database management. Think of a library with an old fashioned card based catalog. If you go to a journal and want to read one of the citations you have to physically go back to the central catalog and if lucky, and it is well maintained, then it will direct you to where the citation reference is physically housed. The central catalogs are typically held at the library. You can then go to the new location and retrieve the citation. If the location is a library that you cannot physically visit you contact the library and get an inter-library loan. Ouch. Of course anyone under 35 will probably have no idea about card catalogs. Go look them up and then ponder why in these advanced times we basically use database approaches that are about as inefficient and clunky as that!
Create a different structure - Links to similar information
So what is the alternative? Think of how you might browse journals these days. You expect a citation to have a hyperlink embedded within it. It’s like being on the equivalent of a magic carpet, being transported from citation to citation. The hyperlinks contain the knowledge of where the journal referenced is stored. In other words, hyperlinks are links in context to other relevant material.
Abstracting from this very old world analogy, what we are talking about is essentially linking of relevant ideas. And, if we set the hyperlinks up to link by content rather than location then we can create a structure that makes hyperlinks far more efficient.
If you can retrieve relevant data efficiently, then of course you can assemble information to any purpose coherently. From single customer view to identification and so forth.
So technically, what does this look like?
With Welcomer, database records have additional hyperlinks that connect similar data items for the same person in two other databases. The databases are created by different applications and organisations who are charged with only releasing information to authorised people. As the data is about the person and it is linked to the same data the person is authorised to access it. The application the person is using to access the data has also been authorised by the organisation responsible for the data.
This gives rise to the data structure.

This structure is different to an index structure. It is an abstraction that creates a set of links that we can consider as a whole. Instead of thinking about each individual elements across all the databases as separate elements we can label the polygon ABCDE as the NAME of a person. The value of the NAME will vary across the different databases, but the whole polygon is still considered a NAME. In one database it might be Lisa, in another Lisa Schutz, in another it is misspelled as liza Schutz, in another misspelling it is Lisa Schultz and in another the NAME is Schutz.
These databases will have other information in them. In A, B and C we might have ADDRESS. In D and E we might have SALARY. ADDRESS and SALARY will have their own polygons of connections to other databases.
If these data elements are connected for the same person it can be visualised as a set of polygons that together create a polyhedron.
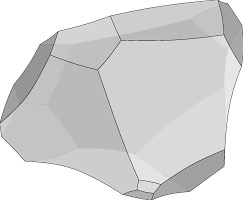
This data structure gives us an abstraction to reason with and implement as program code. The approach is a general approach to connecting distributed data and brings structure and modelling to hyperlinked systems.
It can work for any real world thing be it information about people, cars, houses. Whatever.
Making It Real – Keeping Addresses Up To Date
The unfortunate fact for IT teams is that people change address. As a result of this unfortunate fact, a high proportion of address data is today out of date and inconsistent because people tend to not notify every organisation or database they interact with of a change of address.
A "home address" can be a data element within a Welcomer connected database and all the "home addresses" can be linked by a Welcomer polygon. Each of the "home addresses" reside in their own, respective databases which might include Government tax records, drivers registration, insurance policies and doctors records. The "home address" might be the place the person lives, the place to deliver parcels, or the place they lived when the transaction that created the "home address" was made. At each database the rules for changing the "home address" are specified and defined as part of the local database. When any "home address" in any of the databases changes then a message can be sent along the polygon path with the changes and each database makes its own decision using predefined rules on whether or not to update the "home address".
Importantly the decision made on address is a characteristic of each database and the decision for each database is made asynchronously and independently of any other database. No other database knows if any of the other databases changed the address. All they know is that somewhere the address was changed. In other words we have a distributed database function where each distributed component acts independently. This requires no coordination across databases. It means that when data is changed in one database the same data held in other databases is changed, if required, but only at the time needed.
Making it Real - Verification of Identity
In many societies Electronic Proof of Identity is provided by a person proving they have possession of documents that show they are uniquely identified by organisations. Examples are an ID card, a driver's license, a passport, a relationship with a financial organisation. When a person wishes to uniquely identify themselves to another organisation they use one or more of these documents to prove their uniqueness. The organisation gives them another unique id so the organisation can retrieve information they store about the person when the person identifies themselves to the organisation.
With Welcomer Enabled databases a similar process is used except that the unique ids established with each connected organisation are used to establish new unique ids for other organisations. This contrasts with using the same physical ids for each new organisation.
A person goes to the new organisation (let’s call it bank D). They assert that they have a prior relationship with Organisations B, C and E. They give permission for D to use its already established organisational links with B, C and E to check if they do have those relationships and if so, then D creates a unique ID that is only known to D. And, in turn the person takes their unique ID for the organisation and adds it to their personal polyhedron. Now, if the person goes to another participating organisation, they can assert that they have unique IDs with B,C,E and D.
A Welcomer ID is an emergent property of the connected polygon of unique ids created for Welcomer enabled databases. A personal ID polyhedron if you will.
The advantage of this method is that like the internet, as long as there is an intermediate linkage(s) no two organisations need to be directly connected. And, the raw data typically used for verification of identity can be used as a secondary confirmation. The approach relies on the fact that all entities have allocated unique IDs to other entities to which they are connected and the fact that the unique ids are connected through a unique ID polygon.
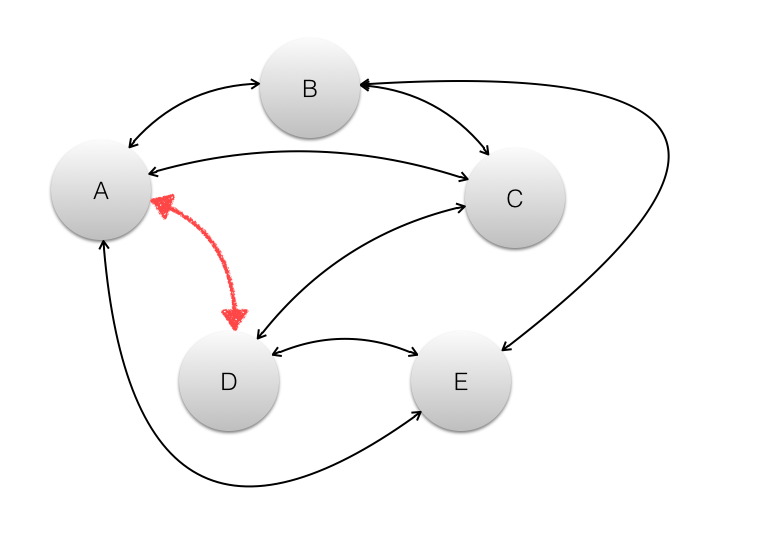
In the diagram the entities A, B, C, D and E are represented by bubbles. A is a person. B,C,D and E are organisations. The lines represent connections between entities.
To take you through the example above, again, more technically, now that A is entering into a banking relationship with Bank D, the link AD is to be added. For AD to be created the rule specified by D is that there be 3 confirmations that A is unique with three other trusted entities. The person A also sets the rule that it wants D to be uniquely identified by three other entities. A sends a message around its polygon of unique ids and asks if at each entity there is a relationship with D. D sends a message around its polygon of unique ids and finds the number of unique instances of A.
If both A and D establish that the other has three instances from the messages sent back to them then the link AD is established by each putting its unique id for the party in its own polygon of unique ids.
It is important that the ID that A gives D is only known to A and the ID that D gives to A is only known to D. Public key pairs for identity overcome the problem of passing unique IDs around the system.
The approach works for other entities such as companies, trusts, not for profits, etc. as A, B, C, D, or E can be any type of entity. The system also works for other things such as a motor car, a house, a computer, or any object in the Internet of Things. The graph of interconnecting identities is not just for people. It means that any type of entity can act as verifying identity for any other entity. This means if a person owns a house and the ownership of the house is recorded in a Welcomer connected database the house can be used to verify the identity of the house owner.
The number of unique IDs can vary with the confidence required. A newborn baby may initially be linked to just one parent, then other people and other organisations can be linked.
The database of common identity information and links to other unique ID polygons for an individual will initially be stored in Verification of Identity application databases but there is no logical reason why every person could not move their database of connections and ID information and store it on their own phone where the phone becomes the electronic representation of the person.
A person can have many separate polygons of unique IDs. It may be that a person wants to have different IDs for social connections, for family connections and for business connections. All these can be kept independent and separate from each other.
Verification of identity is a continuous process. Each new verification strengthens the trust in the existing verifications. It means that anomalies in behaviour can be detected and confirmation of identity can be required if fraud is suspected.
This form of identity verification can be deployed rapidly in any society by making existing large databases of personal data Welcomer Enabled. If births, deaths and marriages, passports, social security IDs, tax records, drivers licenses, visas, bank accounts were Welcomer Enabled then this would be sufficient to cover most people. People could create their polygons of unique ids the first time they accessed any services by any of these organisations. They could later use their official identities to create other trusted identities for other purposes.
Making it Real with Biometric Authentication
Biometrics are a convenient simple way for a physical person to be authenticated (linked to a computer record). Assume Welcomer is used to verify the identity of a person and voice authentication is wanted to confirm it is the same person using the verified identity. To do this a voice print can be part of each unique id record. When a new connection is made a voice print for the person can be combined with all the other existing voice prints across all the unique ids. The new connection is not made unless the voice print, or an alternative authentication, is established. Each time the voice is used in any application it strengthens the combined voice print across all applications.
Making it Real with Programs
The Welcomer links are not synchronous in the sense of database records where all the data elements in a record are retrieved when a record is read. Welcomer communication is achieved by passing messages along links and communication is asynchronous. The system addresses records by content rather than by location. An index or ID for a record asks for a particular data record to be retrieved. With Welcomer messages a value of a data element is retrieved by broadcasting a message along connected links and asking for the record with given content to respond. This approach is implemented with reactive programming technology where the Open Source Welcomer software provides APIs to applications to add a new data link and to retrieve data element values via these data links.
Linking database records with the same data elements reduces the potential hyperlink address space and makes the approach scalable, relatively easy to program and makes it possible to optimise performance.
Welcomer is implemented with the use of Akka programming framework from TypeSafe.
Making it Real by Connecting Applications
Organisations control the reuse of data by defining the data elements linked across applications. Applications call Welcomer APIs to access the data and the data linkages are defined when the applications are deployed. Welcomer publishes a list of APIs, and a list of data element definitions in Welcomer Enabled applications. The organisation deploying an application specifies the data elements it thinks are the same in other applications.
Rules on access to data are defined in Welcomer and reside in each Data Silo. These rules are private to the Data Silo who may or may not release the rules.
For example, a person may not be able to access data unless the person has had their identity verified in three other places, and they have authenticated themselves with two factors such as Voice Print and email address.
An organisation may not wish other specified organisations to view data and/or may want to only allow specific organisations to view data.
Another rule may be to know the data exists but not to be able to access it.
To Know More
Welcomer is committed to deploying the connections with open source software and invites anyone to contribute to and use the code. Using it in applications will enable the data stored and accessed by the application available to any other application that uses the code. Using the approach within an organisation will save much money and remove the need for other approaches to providing a single customer view as an alternative or in parallel to Single Signon. Used widely the software will reduce the cost of building and operating computer systems by billions of dollars each year. To know more about the approach and see examples of Welcomer at work visit http://welcomer.me.