
This article puts the proposition that Electronic Identity, Electronic Personal Privacy is enhanced by giving people access to previously entered data so they can reuse the data in different circumstances. This objective of giving people, enter once - use many times, is valuable in its own right and it also addresses the problem of leakage of personal data from existing organisational data silos of personal information. The article proposes an algorithm that implements both the reuse issue and helps prevent leakage of personal data. Identity and the sharing of personal data pervades the Internet. It is the foundation for the trust we have in electronic relationships with organisations and with other people. Trust in data is built on knowing that the data provided is accurate and refers to the person concerned.
The Internet has allowed data to be easily shared and transmitted. Personal data is held in organisation databases where the organisation takes the responsibility of identifying the persons and keeping the data secure and private. These systems are successful and work well. Within this ecosystem there is a need for organisations to exchange personal data within their own boundaries and across organisational boundaries. Individuals by law are required to approve the transmission of personal data and the purposes to which the data can be used. In most cases organisations find it in their best interests to keep personal data private and follow the law.
This organisational centric system works reasonably well for organisations internal operations. It becomes difficult for organisations when data is used for purposes other than the reason collected and when it is moved across organisations. It does not work well for individuals because they have no easy way of reusing data they have previously entered and they must continually give permission for data to be transmitted.
Organisations overcome some of these difficulties by subscribing to surveillance services and by using big-data techniques to profile users. Both these approaches are at odds with the objectives of maintaining privacy and of organisations keeping data in silos and organisations protecting their data.
To address this problem we need ways for individuals to easily reuse previously entered data with the agreement of the organisations who have the responsibility for keeping the data secure. There are many suggestions on how this can be done. Most centre around the idea of people owning their own data and when the data needs to be shared the person collects it and distributes it. To reduce the sharing effort these system often include methods of providing user defined ways organisations can access information without explicit permission each time it is used. The difficulties with these approaches are they lead to centralisation of information about a person or centralisation of pointers to information about a person. They sometimes require user permissions to allow access before the permissions are required. They create personal data stores of the data about a person from organisations but stored outside the control of the organisations responsible for the data.
The algorithm presented here is a different approach based on the idea of easily reusing personal data across organisational silos of information. The algorithm is implemented in applications and results in previously entered data being made available to a person for use in other applications. The algorithm is called PEDDAL (PErsonal Distributed Data ALgorithm). It works on the principle that when a person goes to enter data in a PEDDAL application then all the previous instances of the data in PEDDAL applications are available to the individual. The data entered into the new application is then made available to other applications.
Organisations control and only allow PEDDAL to operate on data in applications they are willing for people to reuse. Data access is contextualised by the application that wishes to use the data rather than around the data itself. The use of PEDDAL applications results in a person having easy access to previously entered data items. This in turn makes it easier for individuals to supply data to organisations rather than organisations having to rely on surveillance and big-data profiling to obtain the data.
Applications that use PEDDAL must be approved by each organisation that allows it to access organisational data. The data associated with PEDDAL is kept within the administrative boundaries of the organisation responsible for the data. Existing applications remain as they are but if they use PEDDAL then they become part of the PEDDAL network.
For an organisation to use PEDDAL applications or to add PEDDAL to existing applications the steps are:
- The organisation approves the application and approves which organisational data can be accessed by other PEDDAL applications and any restrictions that might apply to the access.
- An individual uses an application and for data items that are PEDDAL enabled they either select from previously entered data or enter new data.
We have implemented a MVP version of the algorithm which we call making an application Welcomer Enabled.
A short description of PEDDAL
- When asked to enter a data item the individual has the option of selecting the value from a list of the data entered in other applications.
- After the data is entered it put it in the list of previously entered data and made available to other applications.
The structures created from using PEDDAL compared to the structure of data in other systems
The list of data is implemented as a doubly linked circular list where the data elements are held in different applications that may or may not be in different organisations.

This can be thought of as ring of data.
With almost all other systems data is stored in heterarchical storages. This can be thought of as a collection of connected star shapes.
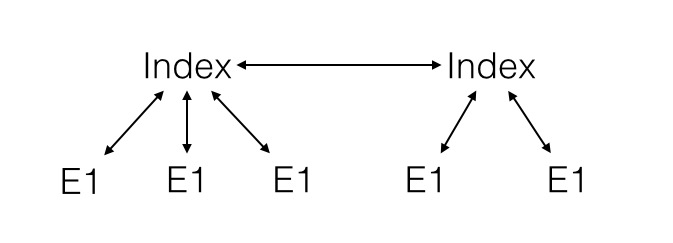
In the large the resulting storage structures for an individual can be represented as a set of linked rings resulting from the use of PEDDAL or a set of clusters resulting from the use of traditional index based storage structures.


The interlinked ring structure is visually and in practise more integrated and robust than index based systems. The ring structure is completely distributed but completely interlinked so that once an algorithm has access to one ring then it potentially has read access to all data on all rings.
Some Outcomes of using the PEDDAL Algorithm to create rings of interconnected data items
Using PEDDAL means:
- Individuals enter their data once and can reuse it many times.
- The individual has access to where the data has been used and can request the data be changed in different places with a data change application.
- Credential data can be shared across many applications and so achieve single signon.
- A person can verify their identity by reference to their connections with other organisations and applications.
- Biometric data can be used across organisations and applications in a way that maintains privacy and only requires one copy of the biometric being used.
- Sensitive data such as location can be controlled by the individual and only released for specific purposes and only kept in a ring structure.
- Organisations only need to collect and maintain minimum personal data for an individual to conduct most transactions as transient data can be obtained elsewhere.
- There is no central repository of information about a person as the data is kept in existing silos
- The level of security for any transaction can be tuned to the risk associated with the transaction
- Users can control applications that access the PEDDAL distributed data for their own purposes including ensuring their personal data is not being compromised.
Description of the PEDDAL Algorithm
The PEDDAL algorithm is implemented as a two stage system. The first stage is deploying the algorithm in organisational applications in a controlled manner. The second stage is the use of the algorithm by individuals accessing their data. The first stage creates the framework and rules for how the rings are formed. The second stage is the creation of the rings of data elements.
Stage 1 Setup
- A is an application that makes a copy of data held by an organisation O
- The data copy is broken into elements E.
- R are the rules applied by the organisation to the reuse of the copy of the Data through an application A.
- An organisation O explicitly agrees to an application being able to access data items by including the application in its catalog and by providing a certificate for the application to access data.
- The organisation creates a catalog of the elements in applications that have been permitted to access their data elements and specifies the rules R for access. (A, E, O, R)
- Each time a person uses an application with an organisation they identify themselves to the organisation.
Stage 2 Use
- If a person wishes to reuse a data element held by another organisation they identify themselves to each organisation independently and link the two data elements provided the rules R for both organisations allow it.
- When one data element is reused in an application then all other data elements in the application are potentially available for reuse in any other approved application.
The application of this algorithm creates independent networks of linked personal data elements E accessed by a particular individual.
Examples of rules:
- A data item cannot be reused unless the person has been identified in three independent ways. (the default rule is that the person is identified independently in two ways)
- The source of a reused data element can only be revealed to specified organisations. (the default rule is that the source of a data element is not revealed)
- If a data element is changed then the change can be notified to all other copies of the data element. (the default rule is that data elements do not notify others of changes).
- The person making the request to view data must supply proof that they have recently established a link between themselves and the electronic request in at least two different ways in the last half hour. (The default for access is one factor. The default to change the data is three factors)
Example of applying Peddal.
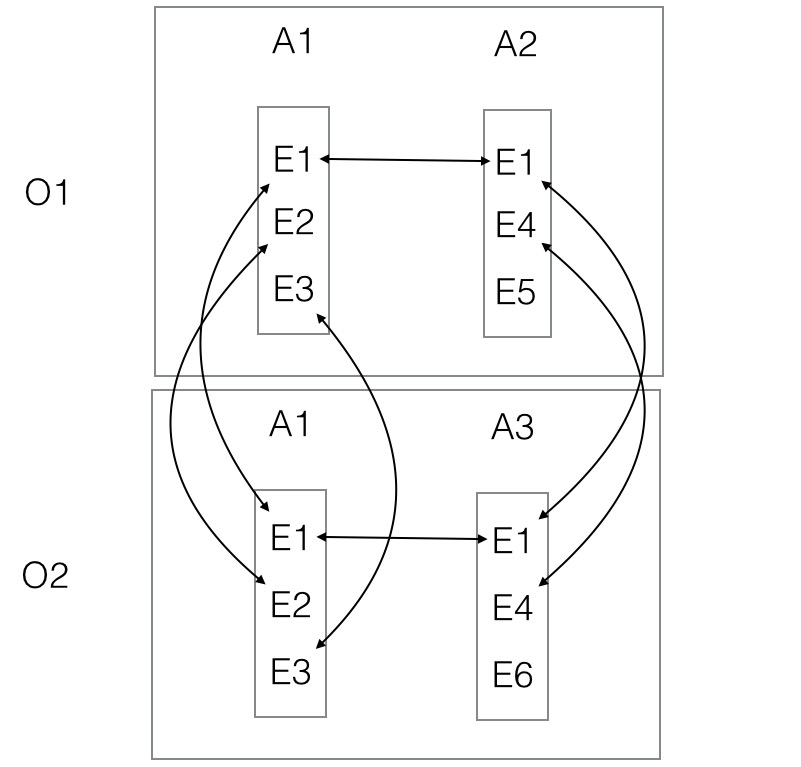
- Organisation O1 has two applications A1 and A2. A1 has elements E1, E2, E3. A2 has elements E1,E4,E5
- Organisation O2 has two applications A1 and A3. A3 has elements E1, E4, and E6
- A person uses applications A1 and A2 with organisation O1 which links E1 in A1 and A2
- The same person then uses application A1 with O2. This links E1 in A2 and A1 of O1 and E2 and E3 in A1 of O2
- The same person then uses application A3 with O2. This links E1 with with A1 in O2 and enables E4 in A2 in O1 to be linked to E4 in A3 in O2.
- Note that E1 is put into a two way circular list connecting all occurrences of E1 across all applications and all organisations.
Results of applying this algorithm
- This algorithm will result in the creation of a ring structure of the same data element for each individual that uses the data element.
- The data elements are connected but they do not know anything else about the other elements in the structure. They can find out by using other approved applications to supply information.
- Applications only store the data elements permanently if the application requires the data in the future. It is expected most applications will only use the data and not store it.
- The structures are distributed and there is no centralised control and no hierarchy of structure.
- The structure is self organising in that an element can decide to go away and automatically connect maintain the ring. When a new application stores data then all the data elements stored in the application are put into their rings.
- The structures are self repairing in that an element can disappear and the ring can regenerate when required.
- The structures can be made to consolidate and to find extra linkages while not being used. This is analogous to short term memory moving into long term memory in the human brain.
- By cutting the rings to an organisation a person can be forgotten to an organisation.